|
Fangyuan MAO I am an incoming Phd student at The Univeristy of Hong Kong, supervised by Prof. Hengshuang ZHAO. Previously, I received my master's degree from ICT CAS and bachelor's degree from Zhejiang University. I am fortunate to have research experiences at ANS@CASICT, Kling@Kuaishou, AMAP@Alibaba, VIPA@ZJU. I believe math and physics are the answers to artificial intelligence. I am trying to integrate more math knowledge with my research. My interests includes generative model, computer vision. Email: fangyuanmaocs@gmail.com, fymao@zju.edu.cn |

|
Education
|
Internships
|
Selected Publication* indicates equal contribution. |

|
Omni-Effects: Unified and Spatially-Controllable Visual Effects Generation
Fangyuan Mao*, Aiming Hao*, Jintao Chen, Dongxia Liu, Xiaokun Feng, Jiashu Zhu, Meiqi Wu, Chubin Chen, Jiahong Wu, Xiangxiang Chu AAAI, 2026 paper / video / project page / code / dataset 
Unified and spatially-controlable visual effects generation pipeline. Omni-Effects supports prompt-guided and SAP-guided Multi-VFX. |

|
PID: Physics-Informed Diffusion Model for Infrared Image Generation
Fangyuan Mao, Jilin Mei, Shun Lu, Fuyang Liu, Liang Chen, Fangzhou Zhao, Yu Hu Pattern Recognition, 2025 paper / code 
|
|
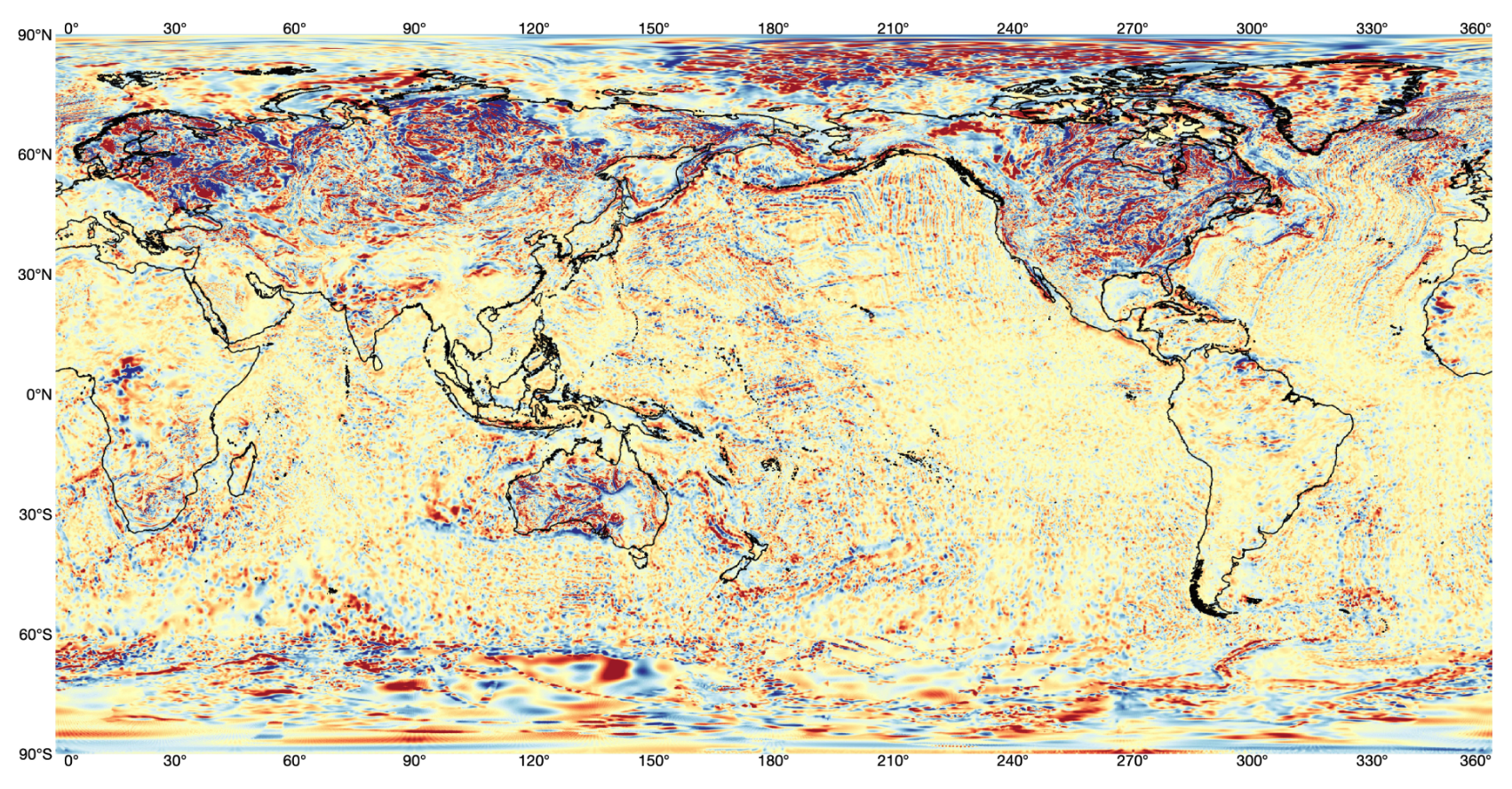
Recovering Missing Regions of Earth Magnetic Anomaly Grid data (EMAG2) Using RePaint based on Diffusion Model
Fangyuan Mao, Bo Yang, Shenyao Jin Big Data and Earth System, 2025 paper / code / dataset |
|
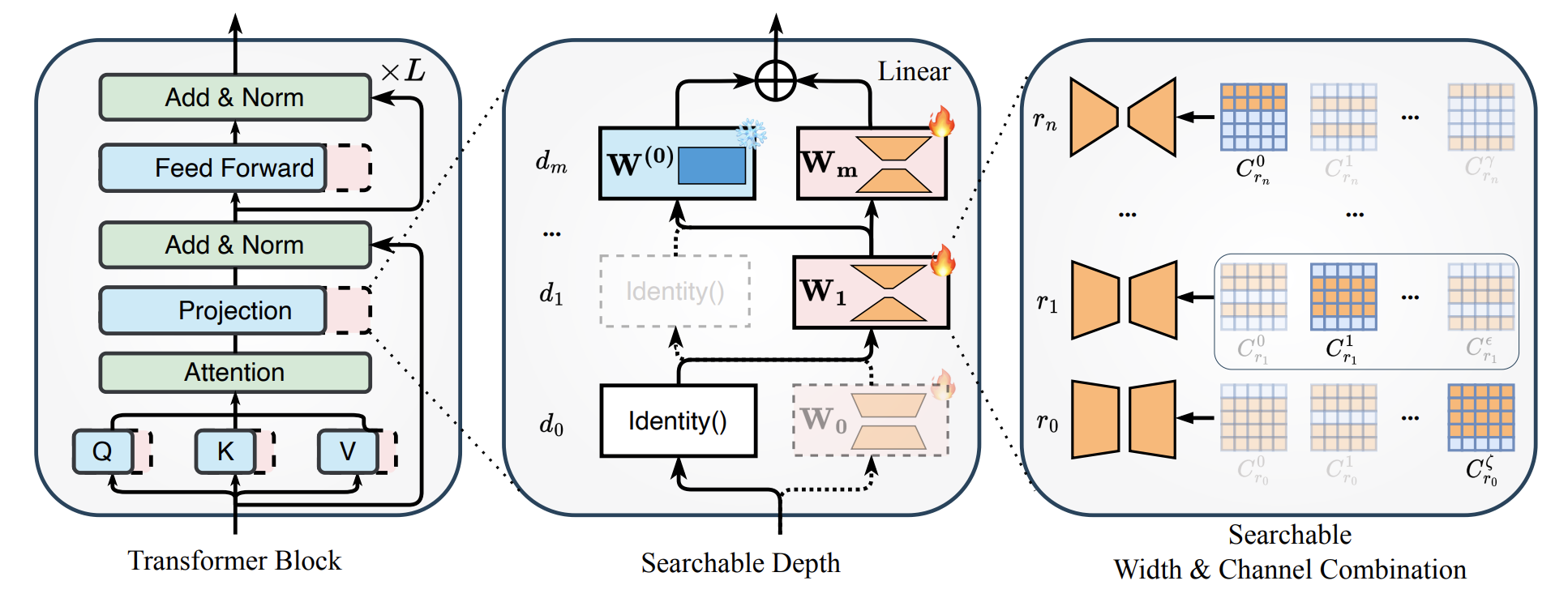
SEA: Hierarchically Searching Efficient Adapters for Pre-trained Models
Shun Lu, Fangyuan Mao, Junkun Chen, Jilin Mei, Chen Min, Yan Xing, Yu Hu Neural Network, 2026 paper / code 
|
|
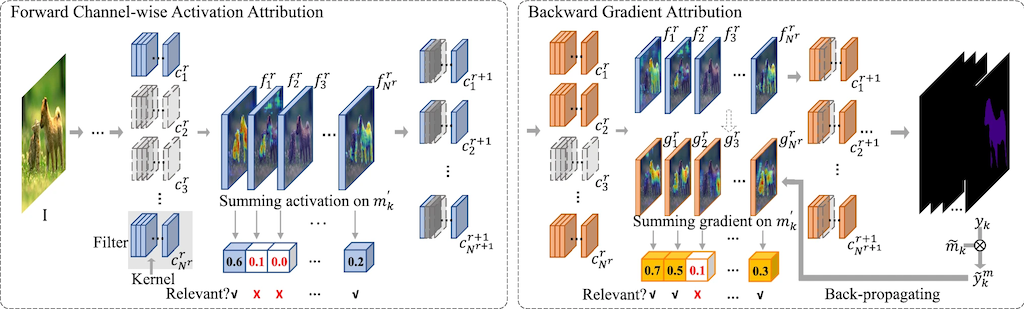
Disassembling Convolutional Segmentation Network
Kaiwen Hu, Jing Gao, Fangyuan Mao, Xinhui Song, Lechao Cheng, Zunlei Feng, Mingli Song IJCV, 2023 paper |
|
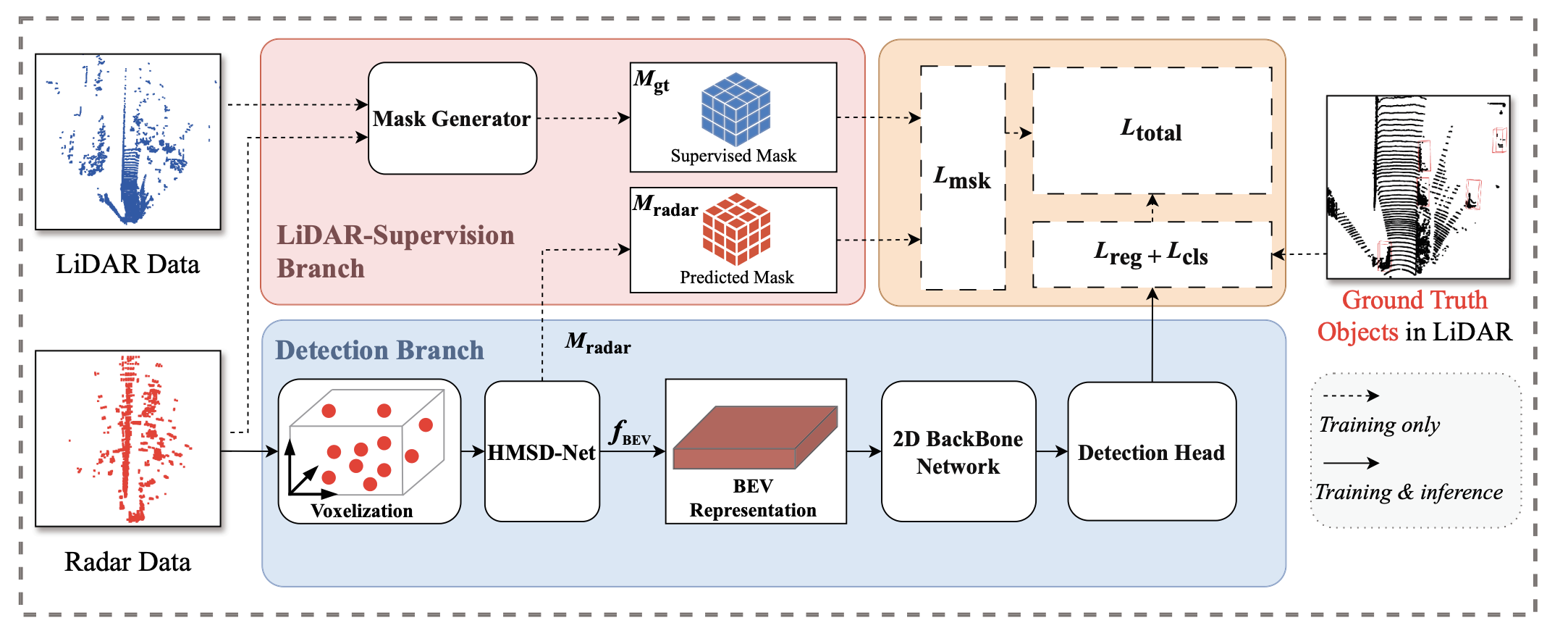
CORENet: Cross-Modal 4D Radar Denoising Network with LiDAR Supervision for Autonomous Driving
Fuyang Liu, Jilin Mei, Fangyuan Mao, Yu Hu, Chen Min, Yan Xing IROS, 2025 paper / code 
|

|
Enhancing Train-Free Infinite-Frame Generation for Consistent Long Videos
Xiaokun Feng, Jiashu Zhu, Meiqi Wu, Chubin Chen, Fangyuan Mao, Haiyang Guo, Jiahong Wu, Xiangxiang Chu, Kaiqi Huang ICML, 2026 paper / project page / code 
|

|
Stochastic Self-Guidance for Training-Free Enhancement of Diffusion Models
Chubin Chen, Jiashu Zhu, Xiaokun Feng, Nisha Huang, Meiqi Wu, Fangyuan Mao, Jiahong Wu, Xiangxiang Chu, Xiu Li ICLR, 2026 paper / project page / code 
|
|
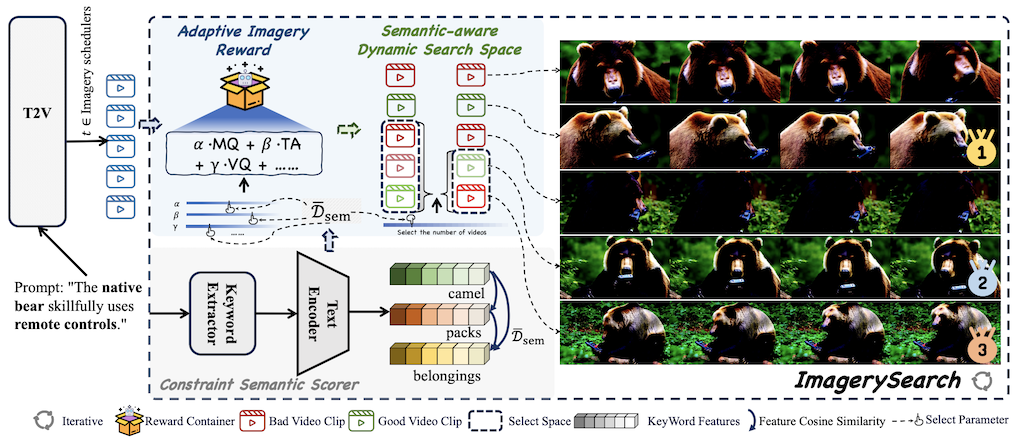
ImagerySearch: Adaptive Test-Time Search for Video Generation Beyond Semantic Dependency Constraints
Meiqi Wu, Jiashu Zhu, Xiaokun Feng, Chubin Chen, Chen Zhu, Bingze Song, Fangyuan Mao, Jiahong Wu, Xiangxiang Chu, Kaiqi Huang AAAI, 2026 paper / code 
|
|
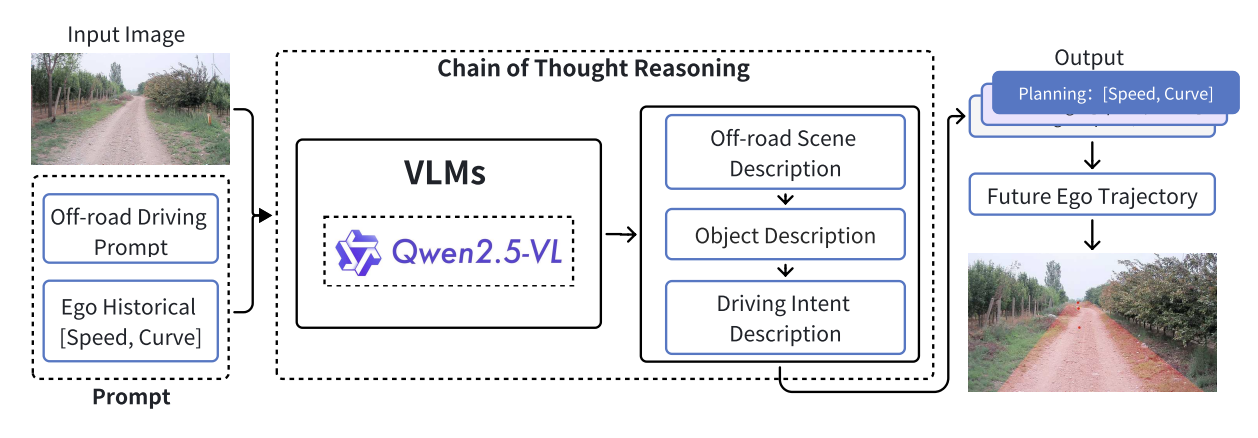
Advancing Off-Road Autonomous Driving: The Large-Scale ORAD-3D Dataset and Comprehensive Benchmarks
Chen Min, Jilin Mei, Heng Zhai, Shuai Wang, Tong Sun, Fanjie Kong, Haoyang Li, Fangyuan Mao, Fuyang Liu, Shuo Wang, Yiming Nie, Qi Zhu, Liang Xiao, Dawei Zhao, Yu Hu ICRA, 2026 paper / code 
|
Preprints |
|
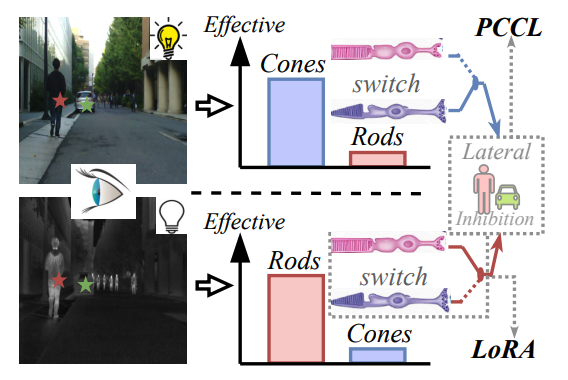
UNIV: Unified Foundation Model for Infrared and Visible Modalities
Fangyuan Mao*, Shuo Wang*, Jilin Mei, Shun Lu, Chen Min, Fuyang Liu, Xiaokun Feng, Meiqi Wu, Yu Hu Arxiv, 2025 paper / code 
|
Awards
|
Reviewer
|